FÖR OMEDELBAR PUBLICERING Nr 3112
Det här pressmeddelandet är en översättning av den officiella engelskspråkiga versionen. Det publiceras endast som praktisk referens för användaren. Läs den ursprungliga engelska versionen för information. Vid skillnader mellan texterna är det den engelska versionen som gäller.
Mitsubishi Electric separerar samtidigt tal från flera oidentifierade personer som spelas in med en mikrofon
Talseparationstekniken uppnås med den patenterade AI-metoden "Deep Clustering"
TOKYO, 24 maj, 2017 – Mitsubishi Electric Corporation (TOKYO: 6503) tillkännagav idag att man har skapat världens första teknologi som separerar, och sedan rekonstruerar med hög kvalitet, samtidigt tal från flera oidentifierade personer som spelas in med en enda mikrofon i realtid. Vid testning separerades samtidiga tal från två och tre personer med upp till 90 och 80 procents noggrannhet, vilket företaget anser att man är först med att uppnå då det här tillkännagivandet gjordes. Den nya teknologin, som förverkligades med Mitsubishi Electrics egenutvecklade metod ”Deep Clustering” baserat på artificiell intelligens (AI), förväntas bidra till mer begriplig röstkommunikation och mer noggrann automatisk taligenkänning.
I fallet med två personer som talar samtidigt överskred man 90 procents noggrannhet, vilket är tillräckligt för kommersiella tillämpningar, jämfört med 51 procents noggrannhet med konventionell teknologi. Den nya tekniken kan skilja på kombinationer av flera talade språk och genus. Ovanstående resultat är baserade på perfekta inspelningsförhållanden, inklusive svagt omgivande ljud och personer som talar ungefär lika högt.
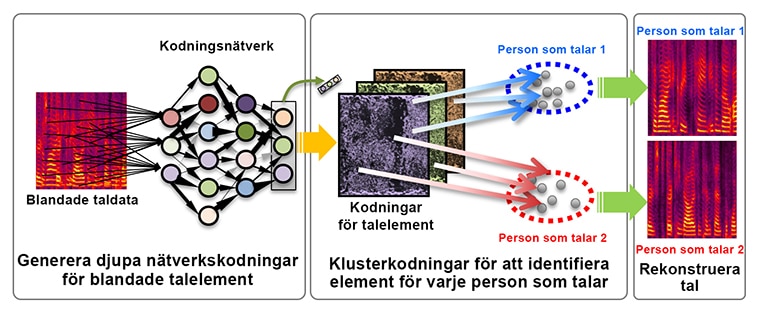
Deep Clustering-tekniken använder Mitsubishi Electrics egenutvecklade djupinlärningsmetod för att lära sig att koda signalkomponenterna i de ursprungliga taldata från flera personer så att signalkomponenterna som hör till varje enskild person enkelt kan skiljas åt utifrån deras kodningar. Detta uppnås genom att kodningarna har optimerats på så vis att olika signalkomponenter som hör till samma person har liknande kodningar, och de som hör till andra personer har olika kodningar. Den inlärda kodningsomformningen tillämpas till tal och kodningarna av signalkomponenterna för varje person som talar identifieras med en klustringsalgoritm som bearbetar datapunkter i grupper beroende på deras likheter. Varje persons tal rekonstrueras sedan genom omsyntetisering av deras separerade talkomponenter.
Noggrannhet i separering av samtidigt tal från flera personer*
| Två personer som talar (en mikrofon) | Tre personer som talar (en mikrofon) | |
|---|---|---|
| Ny teknik | >90 % (först i världen) | >80 % (först i världen) |
| Konventionell teknik | 51 % | ─ |
*Baserat på perfekta inspelningsförhållanden
Observera att meddelandena är korrekta vid tidpunkten för publiceringen men kan ändras utan föregående meddelande.